k8s
运维宝典
kubeflow运维
理解 CNI 和 CNI 插件
GPU虚拟化方案
多个Pod共享使用GPU
Kubernetes GPU共享实践
第四范式GPU虚拟化
腾讯开源vgpu方案gpu-manager安装教程
-
+
首页
腾讯开源vgpu方案gpu-manager安装教程
一、 准备工作 gpu-manager: 源码:https://github.com/tkestack/gpu-manager/tree/master 镜像:https://hub.docker.com/r/thomassong/gpu-manager/tags?page=1&ordering=last_updated gpu-admission: 源码:https://github.com/tkestack/gpu-admission 镜像:https://hub.docker.com/r/thomassong/gpu-admission/tags?page=1&ordering=last_updated 先下载镜像到本地,tag可能需要更新 a) docker pull thomassong/gpu-manager:1.0.9 b) docker pull thomassong/gpu-admission:47d56ae9 二、 部署gpu-manager 从gpu-manager源码复制gpu-manager.yaml到待部署的master机器 修改gpu-manager.yaml a) gpu-manager.yaml,相对源码的修改点见后文 ```yaml apiVersion: v1 kind: ServiceAccount metadata: name: gpu-manager namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: gpu-manager-role subjects: - kind: ServiceAccount name: gpu-manager namespace: kube-system roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: DaemonSet metadata: name: gpu-manager-daemonset namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: name: gpu-manager-ds template: metadata: # This annotation is deprecated. Kept here for backward compatibility # See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/ annotations: scheduler.alpha.kubernetes.io/critical-pod: "" labels: name: gpu-manager-ds spec: serviceAccount: gpu-manager tolerations: # This toleration is deprecated. Kept here for backward compatibility # See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/ - key: CriticalAddonsOnly operator: Exists - key: tencent.com/vcuda-core operator: Exists effect: NoSchedule # Mark this pod as a critical add-on; when enabled, the critical add-on # scheduler reserves resources for critical add-on pods so that they can # be rescheduled after a failure. # See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/ priorityClassName: "system-node-critical" # only run node has gpu device nodeSelector: nvidia-device-enable: enable hostPID: true containers: - image: thomassong/gpu-manager:1.0.9 imagePullPolicy: Never name: gpu-manager securityContext: privileged: true ports: - containerPort: 5678 volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins - name: vdriver mountPath: /etc/gpu-manager/vdriver - name: vmdata mountPath: /etc/gpu-manager/vm - name: log mountPath: /var/log/gpu-manager - name: checkpoint mountPath: /etc/gpu-manager/checkpoint - name: run-dir mountPath: /var/run - name: cgroup mountPath: /sys/fs/cgroup readOnly: true - name: usr-directory mountPath: /usr/local/host readOnly: true - name: kube-root mountPath: /root/.kube readOnly: true env: - name: LOG_LEVEL value: "4" - name: EXTRA_FLAGS value: "--logtostderr=false --incluster-mode=true" - name: NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName volumes: - name: device-plugin hostPath: type: Directory path: /var/lib/kubelet/device-plugins - name: vmdata hostPath: type: DirectoryOrCreate path: /etc/gpu-manager/vm - name: vdriver hostPath: type: DirectoryOrCreate path: /etc/gpu-manager/vdriver - name: log hostPath: type: DirectoryOrCreate path: /etc/gpu-manager/log - name: checkpoint hostPath: type: DirectoryOrCreate path: /etc/gpu-manager/checkpoint # We have to mount the whole /var/run directory into container, because of bind mount docker.sock # inode change after host docker is restarted - name: run-dir hostPath: type: Directory path: /var/run - name: cgroup hostPath: type: Directory path: /sys/fs/cgroup # We have to mount /usr directory instead of specified library path, because of non-existing # problem for different distro - name: usr-directory hostPath: type: Directory path: /usr - name: kube-root hostPath: type: Directory path: /root/.kube ``` b) 修改镜像地址和拉取策略(改为本地拉取) 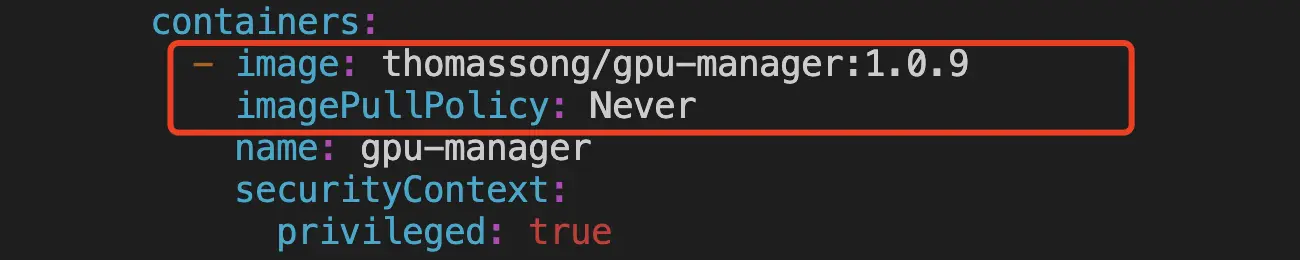 改为本地拉取镜像 c) 增加挂载 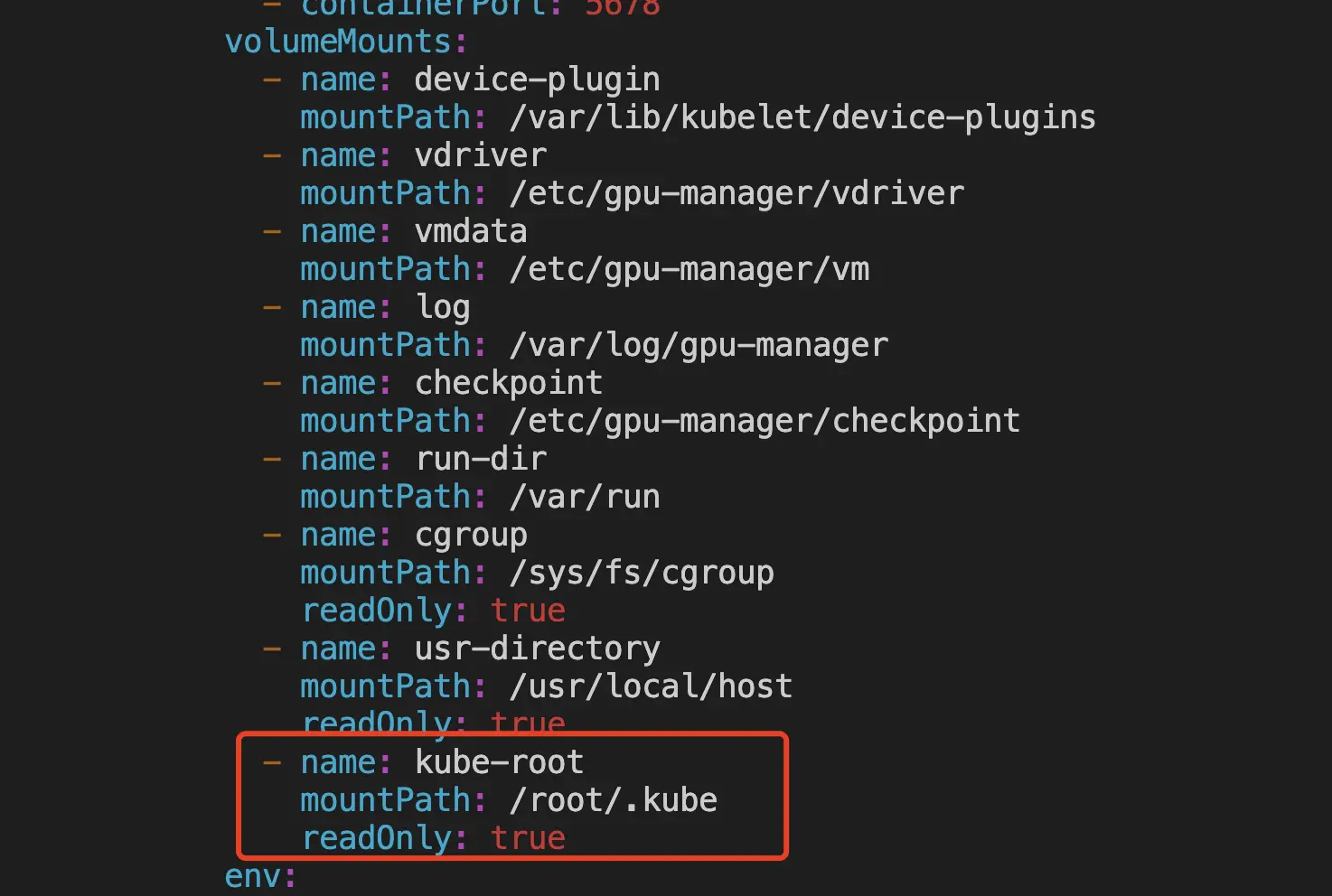 增加挂载 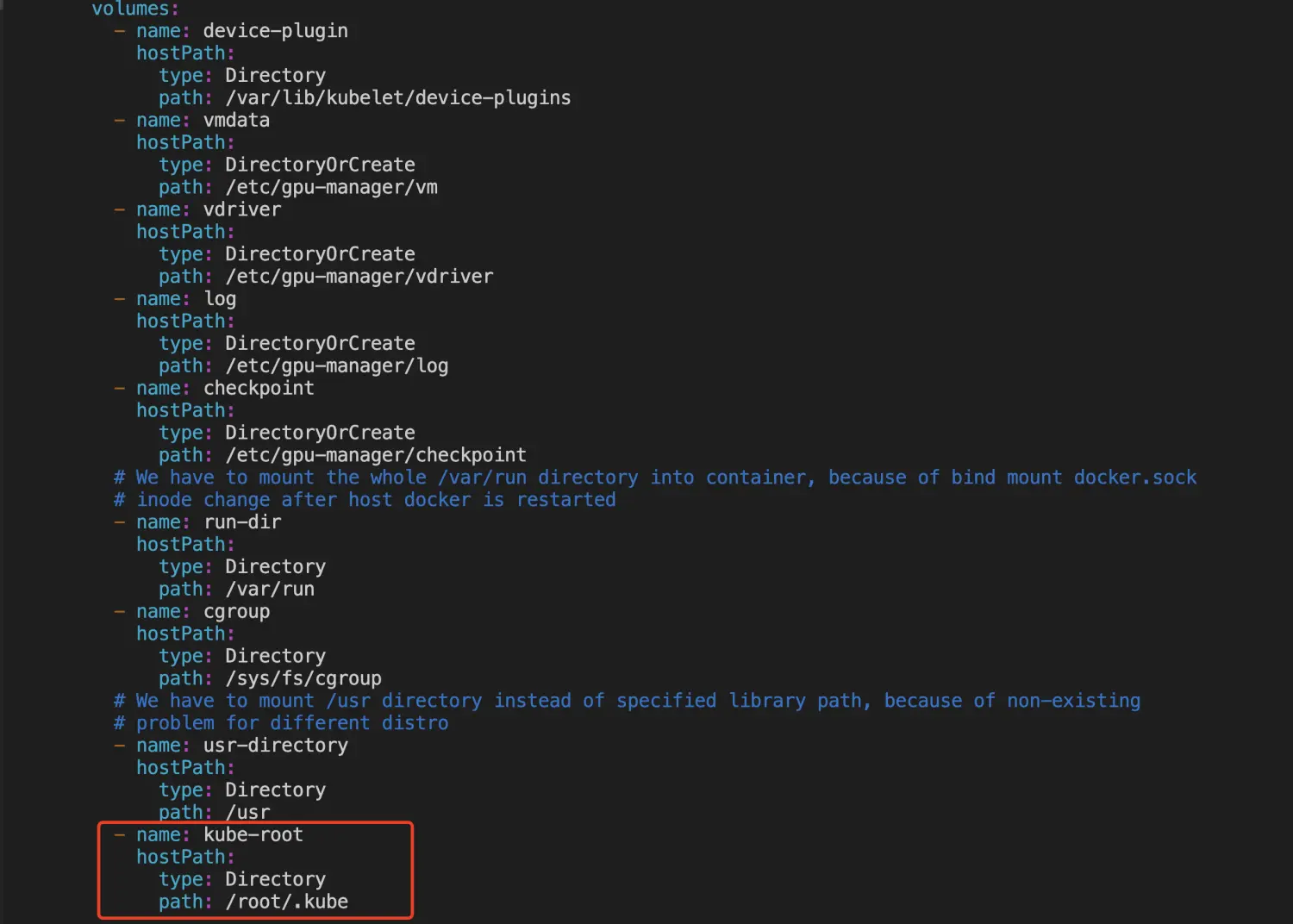 增加挂载 d) 增加启动参数 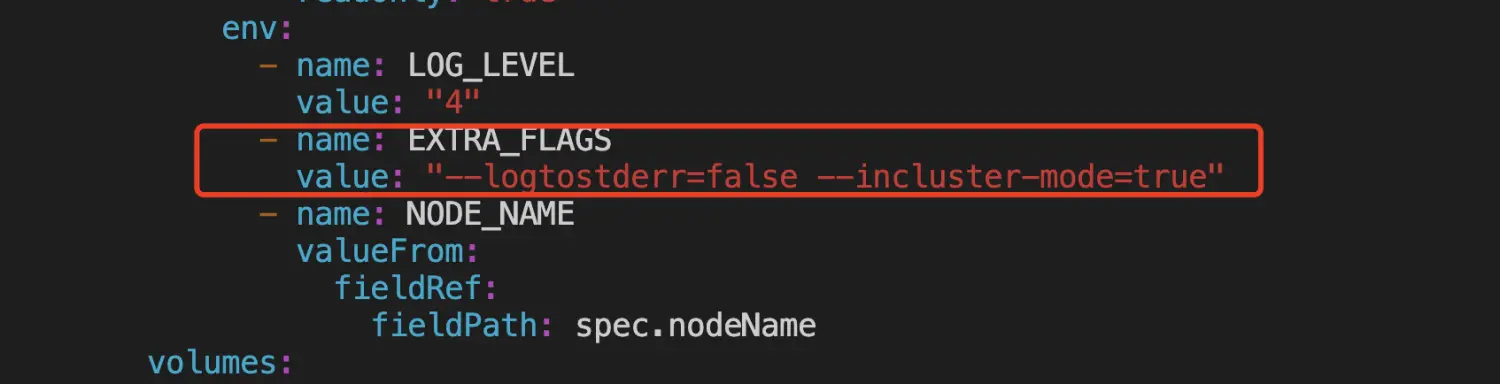 增加启动参数 参考gpu-manager的README执行DEPLOY a) 每个带gpu的node都执行一遍,下面的命令默认所有node都带gpu kubectl get nodes | awk '{print $1}' | grep -v "NAME" | xargs -I{} kubectl label node {} nvidia-device-enable=enable b) kubectl create -f gpu-manager.yaml 三、 部署gpu-admission 源码中的gpu-admission.yaml只部署了单实例,这里使用deployment部署 ```yaml apiVersion: v1 kind: ServiceAccount metadata: name: gpu-admission namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: gpu-admission-as-kube-scheduler subjects: - kind: ServiceAccount name: gpu-admission namespace: kube-system roleRef: kind: ClusterRole name: system:kube-scheduler apiGroup: rbac.authorization.k8s.io --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: gpu-admission-as-volume-scheduler subjects: - kind: ServiceAccount name: gpu-admission namespace: kube-system roleRef: kind: ClusterRole name: system:volume-scheduler apiGroup: rbac.authorization.k8s.io --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: gpu-admission-as-daemon-set-controller subjects: - kind: ServiceAccount name: gpu-admission namespace: kube-system roleRef: kind: ClusterRole name: system:controller:daemon-set-controller apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: Deployment metadata: labels: component: scheduler tier: control-plane name: gpu-admission namespace: kube-system spec: selector: matchLabels: component: scheduler tier: control-plane replicas: 1 template: metadata: labels: component: scheduler tier: control-plane version: second spec: serviceAccountName: gpu-admission containers: - image: thomassong/gpu-admission:47d56ae9 imagePullPolicy: Never name: gpu-admission env: - name: LOG_LEVEL value: "4" ports: - containerPort: 3456 dnsPolicy: ClusterFirstWithHostNet hostNetwork: true priority: 2000000000 priorityClassName: system-cluster-critical ``` 部署kubectl create -f gpu-admission.yaml 获取gpu-admission的ip地址 kubectl get pod -n kube-system | grep gpu-admission | awk '{print $1}' | xargs kubectl get pod -n kube-system -o=jsonpath='{.status.hostIP}' 新建/etc/kubernetes/scheduler-policy-config.json,填入上一步获取的ip { "kind": "Policy", "apiVersion": "v1", "predicates": [ { "name": "PodFitsHostPorts" }, { "name": "PodFitsResources" }, { "name": "NoDiskConflict" }, { "name": "MatchNodeSelector" }, { "name": "HostName" } ], "priorities": [ { "name": "BalancedResourceAllocation", "weight": 1 }, { "name": "ServiceSpreadingPriority", "weight": 1 } ], "extenders": [ { "urlPrefix": "http://${gpu_quota_admission_ip}:3456/scheduler", "apiVersion": "v1beta1", "filterVerb": "predicates", "enableHttps": false, "nodeCacheCapable": false } ], "hardPodAffinitySymmetricWeight": 10, "alwaysCheckAllPredicates": false } 创建/etc/kubernetes/scheduler-extender.yaml apiVersion: kubescheduler.config.k8s.io/v1alpha1 kind: KubeSchedulerConfiguration clientConnection: kubeconfig: "/etc/kubernetes/scheduler.conf" algorithmSource: policy: file: path: "/etc/kubernetes/scheduler-policy-config.json" 修改/etc/kubernetes/manifests/kube-scheduler.yaml,修改完后kube-scheduler会自动重启 a) kube-scheduler.yaml,修改内容见下文 ```yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: component: kube-scheduler tier: control-plane name: kube-scheduler namespace: kube-system spec: containers: - command: - kube-scheduler - --bind-address=127.0.0.1 - --feature-gates=TTLAfterFinished=true - --kubeconfig=/etc/kubernetes/scheduler.conf - --leader-elect=true - --config=/etc/kubernetes/scheduler-extender.yaml image: ccr.ccs.tencentyun.com/k8s-comm/kube-scheduler:v1.14.3 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 8 httpGet: host: 127.0.0.1 path: /healthz port: 10251 scheme: HTTP initialDelaySeconds: 15 timeoutSeconds: 15 name: kube-scheduler resources: requests: cpu: 100m volumeMounts: - mountPath: /etc/kubernetes/scheduler.conf name: kubeconfig readOnly: true - mountPath: /etc/localtime name: localtime readOnly: true - mountPath: /etc/kubernetes/scheduler-extender.yaml name: extender readOnly: true - mountPath: /etc/kubernetes/scheduler-policy-config.json name: extender-policy readOnly: true hostNetwork: true priorityClassName: system-cluster-critical volumes: - hostPath: path: /etc/kubernetes/scheduler.conf type: FileOrCreate name: kubeconfig - hostPath: path: /etc/localtime type: File name: localtime - hostPath: path: /etc/kubernetes/scheduler-extender.yaml type: FileOrCreate name: extender - hostPath: path: /etc/kubernetes/scheduler-policy-config.json type: FileOrCreate name: extender-policy status: {} ``` b) 增加运行参数,如果调度出现问题,删除此行可恢复为默认调度策略 增加运行参数 c) 增加挂载 增加挂载 四、 验证 检查kube-system下的相关pod是否正常Running 检查运行状态 检查gpu node带有显卡相关资源配置 kubectl describe node node-xxx.k8s 检查资源配置 修改Deployment或者StatefulSet的配置,为容器调度配置gpu资源。注意这里vcuda-core只能取小于100的整数或者100的倍数,且requests和limits中的vcuda-core和vcuda-memory必须相同。 配置gpu资源 五、 参考文档 https://www.qikqiak.com/post/custom-kube-scheduler/ https://kubernetes.io/zh/docs/tasks/extend-kubernetes/configure-multiple-schedulers/ https://github.com/tkestack/gpu-manager/issues/7
jays
2024年1月9日 21:45
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅道文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅道文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅道文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
下载Markdown文件
分享
链接
类型
密码
更新密码



